Comment by georgewsinger
1 year ago
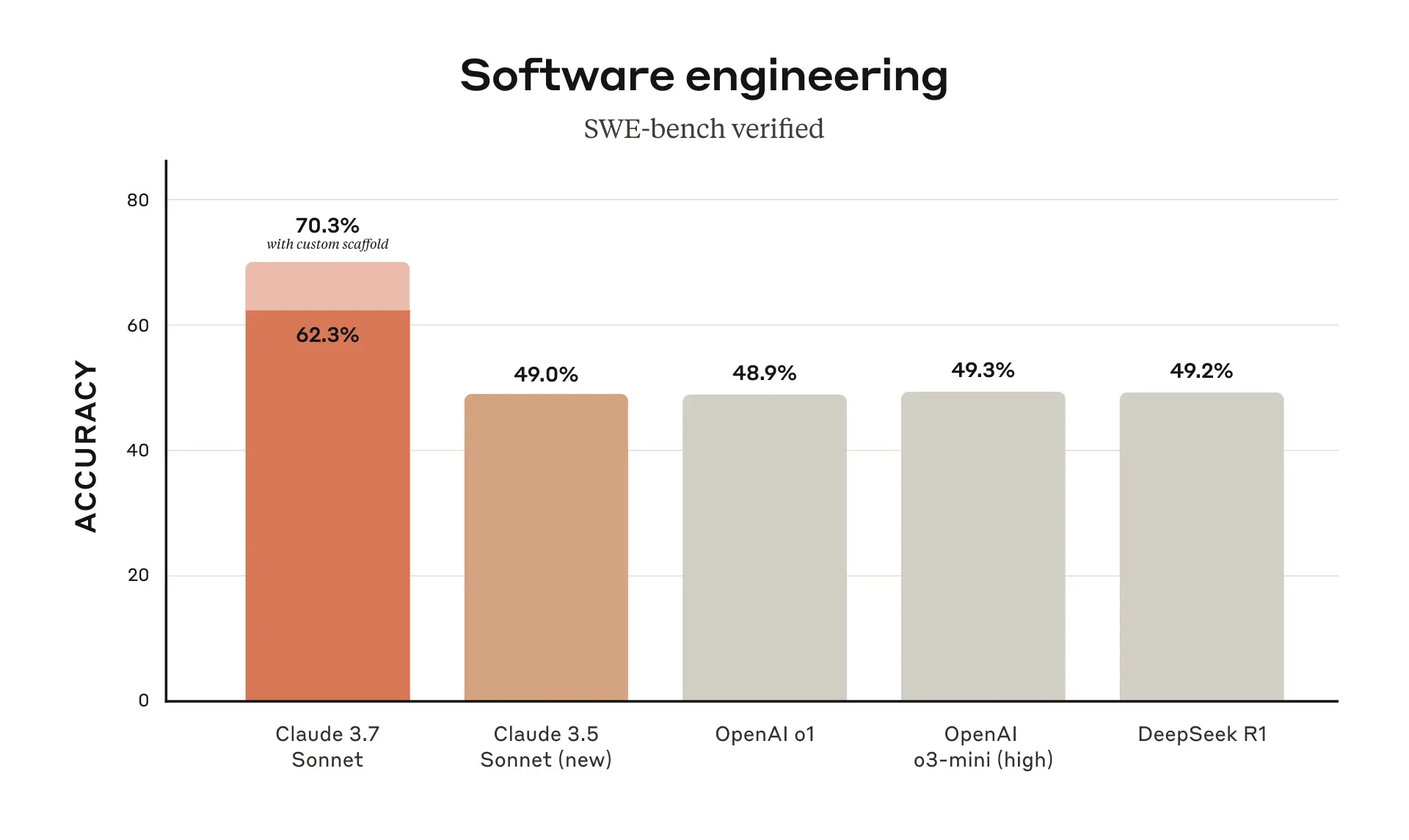
Yes, however Claude advertised 70.3%[1] on SWE bench verified when using the following scaffolding:
> For Claude 3.7 Sonnet and Claude 3.5 Sonnet (new), we use a much simpler approach with minimal scaffolding, where the model decides which commands to run and files to edit in a single session. Our main “no extended thinking” pass@1 result simply equips the model with the two tools described here—a bash tool, and a file editing tool that operates via string replacements—as well as the “planning tool” mentioned above in our TAU-bench results.
Arguably this shouldn't be counted though?
[1] https://www.anthropic.com/_next/image?url=https%3A%2F%2Fwww-...
{kind=link}
I think you may have misread the footnote. That simpler setup results in the 62.3%/63.7% score. The 70.3% score results from a high-compute parallel setup with rejection sampling and ranking:
> For our “high compute” number we adopt additional complexity and parallel test-time compute as follows:
> We sample multiple parallel attempts with the scaffold above
> We discard patches that break the visible regression tests in the repository, similar to the rejection sampling approach adopted by Agentless; note no hidden test information is used.
> We then rank the remaining attempts with a scoring model similar to our results on GPQA and AIME described in our research post and choose the best one for the submission.
> This results in a score of 70.3% on the subset of n=489 verified tasks which work on our infrastructure. Without this scaffold, Claude 3.7 Sonnet achieves 63.7% on SWE-bench Verified using this same subset.
Somehow completely missed that, thanks!
I think reading this makes it even clearer that the 70.3% score should just be discarded from the benchmarks. "I got a 7%-8% higher SWE benchmark score by doing a bunch of extra work and sampling a ton of answers" is not something a typical user is going to have already set up when logging onto Claude and asking it a SWE style question.
Personally, it seems like an illegitimate way to juice the numbers to me (though Claude was transparent with what they did so it's all good, and it's not uninteresting to know you can boost your score by 8% with the right tooling).
It isn't on the benchmark https://www.swebench.com/#verified
The one on the official leaderboard is the 63% score. Presumably because of all the extra work they had to do for the 70% score.