Comment by f_devd
2 years ago
Transformers actually have an quantifiable state size (see https://hazyresearch.stanford.edu/static/posts/2024-06-22-ac...) although it's anywhere between 200k and 2M floats (for 360M and 1.33B respectively iinm). So a sufficiently sized RNN could have the same state capacity as a transformer.
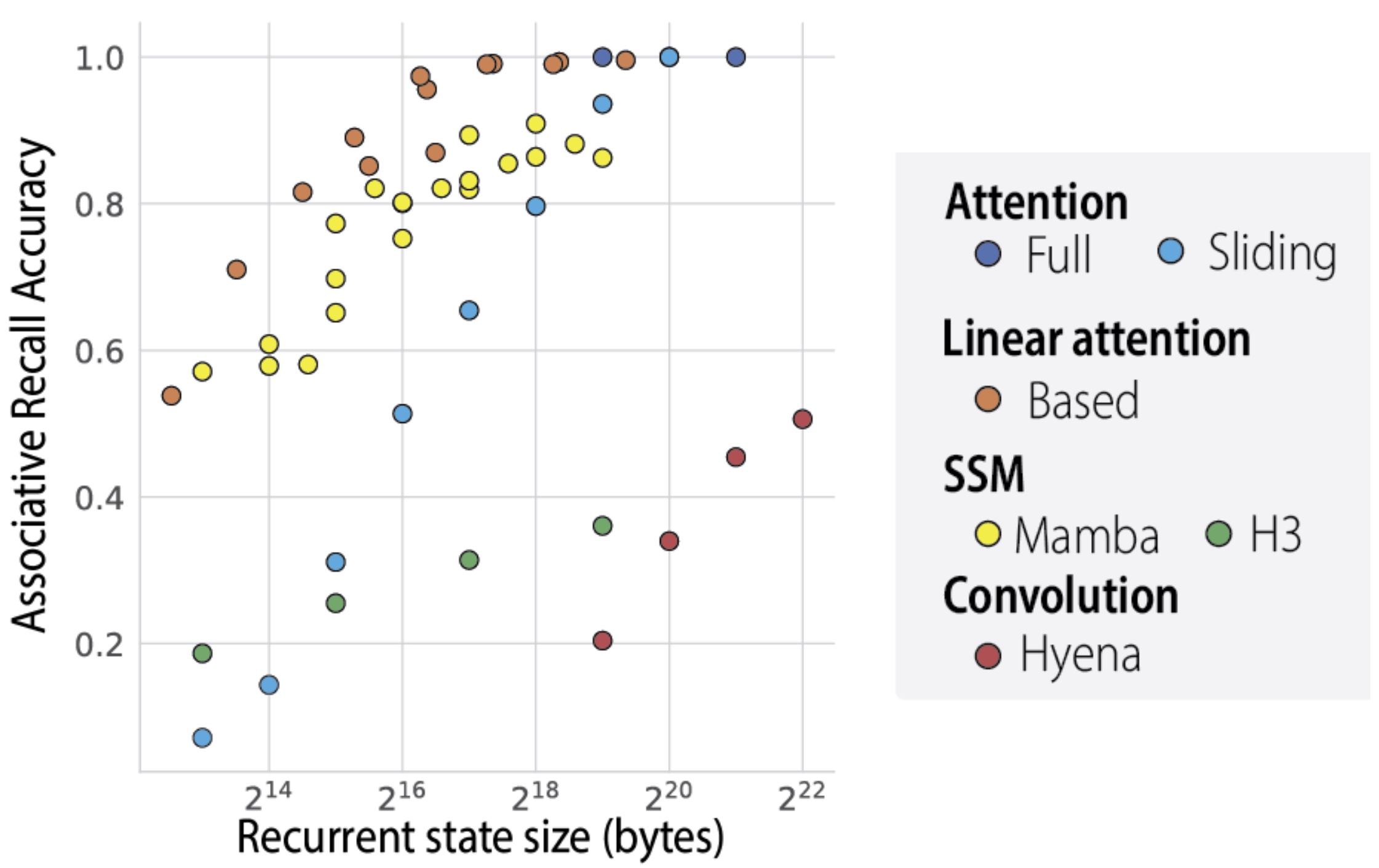{kind=link}
(this is from the Based paper: https://arxiv.org/pdf/2402.18668)
> Transformers actually have an quantifiable state size
Are you griping about my writing O(X^2) above instead of precisely 2X^2, like this paper? The latter implies the former.
> So a sufficiently sized RNN could have the same state capacity as a transformer.
Does this contradict anything I've said? If you increase the size of the RNN, while keeping the Transformer fixed, you can match their recurrent state sizes (if you don't run out of RAM or funding)
I was responding to
> a Transformer layer can look back see O(X^2) numbers, while an RNN can only see O(X) numbers
The thing is RNN can look back infinitely if you don't exceed the state capacity. For transformers the state it is defined semi-implicitly (you can change the hidden dims but you cannot extend the look back; ignoring transformer-xl et al.) defined by the amount of tokens, for an RNN it's defined explicitly by the state size.
The big-O here is irrelevant for the architectures since it's all in the configuration & implementation of the model; i.e. there is no relevant asymptote to compare.
As an aside this was what was shown in the based paper, the fact that you can have a continuity of state (as with RNN) while have the same associative recall capability as a transformer (the main downfall of recurrent methods at that point).
> The big-O here is irrelevant for the architectures since it's all in the configuration & implementation of the model; i.e. there is no relevant asymptote to compare.
?!
NNs are like any other algorithm in this regard. Heck, look at the bottom of page 2 of the Were RNNs All We Needed paper. It has big-O notation there and elsewhere.
> I was responding to
>> a Transformer layer can look back see O(X^2) numbers, while an RNN can only see O(X) numbers
In the BASED paper, in Eq. 10, sizeof(s) = 2dN. But I defined d = N = X above. Ergo, sizeof(s) = 2X^2 = O(X^2).
For minGRU, sizeof(s) = d. Ergo, sizeof(s) = X = O(X).
1 reply →