Ask HN: Weird archive.today behavior?
4 months ago
archive.today has recently (I noticed this, like, 3 days ago) started automatically making requests to someone's personal blog on their CAPTCHA page. Here's a screenshot of what I'm talking about: https://files.catbox.moe/20jsle.png
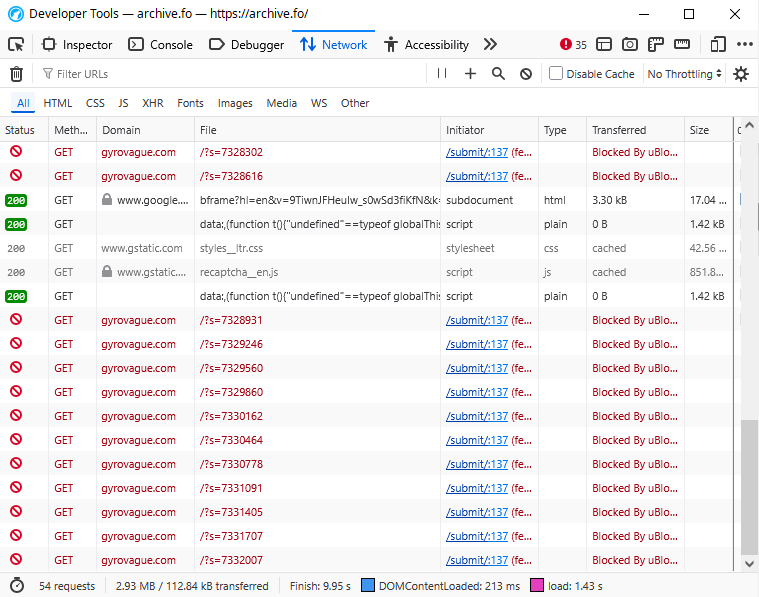{kind=link}
The relevant JS is:
setInterval(function() {
fetch("https://gyrovague.com/?s=" + Math.round(new Date().getTime() % 10000000), {
referrerPolicy: "no-referrer",
mode: "no-cors"
});
}, 300);
Looking at this blog, there seems to be exactly one article mentioning archive.today - "archive.today: On the trail of the mysterious guerrilla archivist of the Internet" (https://gyrovague.com/2023/08/05/archive-today-on-the-trail-...), where the person running the blog digs up some information about archive's owner.
So perhaps this is some kind of revenge/DOS attack attempt/deliberately wasting their bandwidth in response to this article? Maybe an attempt to silence them and force to delete their article? But if it is, then I have so many questions. Like, why would the owner of the archive do that 2.5 years after the article was published? Or why would they even do that in the first place, do they not know about Streisand effect?
I'm confused.
What my pattern-matching eyes immediately spotted is that the hn username that posted this is rabinovich. The linked article speaks about Masha Rabinovich. Maybe a coincidence.
> in a 2012 F-Secure forum post, a “masharabinovich” complains about “my website http://archive.is/” being blacklisted. They pop up on Wikipedia as well getting told off for adding too many links to archive.is, including a mention that they’re using the Czech ISP fiber.cz
> They pop up on Wikipedia as well getting told off for adding too many links to archive.is
Funnily enough, they removed that from their talk page right around the time this thread got posted, their first edit in almost 6 years: https://en.wikipedia.org/wiki/Special:Contributions/Masharab...
That's a lot of coincidences...
Wild idea: Could be a symbolic dead man switch.
Reports of FBI going hard after archive.today around the time the HN account was setup and they post an archive.today competitor. Pings on the investigative article then a post to HN saying “3 days ago” which could indicate when FBI succeeded.
The only comment by the poster on this article is a sharp clarification of what doxxing is and isn’t.
Perhaps this is just an unusual way of slowly stepping out from behind the curtain on your own quirky terms after a fantastically long tenure.
Hmm. If it is an attempt at DDoS attacks, it's probably not very fruitful:
Viewing the first IP address on https://bgp.he.net/ip/192.0.78.25 shows AS2635 (https://bgp.he.net/AS2635) is announcing 192.0.78.0/24. AS2635 is owned by https://automattic.com aka wordpress.com. I assume that for a managed environment at their scale, this is just another Wednesday for them.
I believe they're probably trying to get the blog suspended (automatically?) hence the cache busting; chewing through higher than normal resources all of a sudden might do the trick even if it doesn't actually take it offline.
It is using the ?s= parameter which causes WordPress to initiate a search for a random string. This can result in high CPU usage, which I believe is one of the DoS vectors that works on hosted WordPress.
It occurred to me while reading the article that I could also just have checked the TLS cert. The cert I was given presents "Common Name tls.automattic.com". However, maybe someone will discover bgp.he.net via this :-)
good ol' hurricane electric
> maybe someone will discover bgp.he.net via this
I did, thank you!
1 reply →
This feels like the start of treasure hunt like game. Between username of rabinovich (as others have pointed out) and the prior submission by rabinovich of an archive.today like tool 3 months ago - https://ghostarchive.org/. When you click into the search query examples for ghostarchive such as this one https://ghostarchive.org/search?term=https://docs.google.com. Many of the documents are very weird indeed.
> This feels like the start of treasure hunt like game. Between username of rabinovich (as others have pointed out) and the prior submission by rabinovich of an archive.today like tool 3 months ago - https://ghostarchive.org/. When you click into the search query examples for ghostarchive such as this one https://ghostarchive.org/search?term=https://docs.google.com. Many of the documents are very weird indeed.
This is what someone trying to start a treasure hunt like game would say....
Mom! Am I an NPC? Mom! Am I real???
Well that is a very silly way to punish the author of an article you don’t want people to know about.
"It’s a testament to their persistence that they’re managed to keep this up for over 10 years, and I for one will be buying Denis/Masha/whoever a well deserved cup of coffee."
https://gyrovague.com/2023/08/05/archive-today-on-the-trail-...
And one where the author's cool with whoever is running archive.today.
> And one where the author's cool with whoever is running archive.today.
I don't think it really matters how "cool" you are with someone while actively trying to doxx them.
4 replies →
I never would have read the article had archive.today not gone into a CAPTCHA loop on me and then I see in developer tools it's pinging this other site. Talk about Streisand effect.
I think Streisand effect is the goal. Look at the username of TFA poster and the name of the person the article author suspects.
Remember when Archive.is/today used to send Cloudflare DNS users into an endless captcha loop because the creator had some kind of philosophical disagreement with Cloudflare? Not the first time they’ve done something petty like this.
It wasn't a philosophical disagreement, they needed some geo info from the DNS server to route requests so they could prevent spam and Cloudflare wasn't providing it citing privacy reasons. The admin decided to block Cloudflare rather than deal with the spam.
Had nothing to do with spam, the argument by archive.today that they needed EDNS client subnet info made no sense, they aren't anycasting with edge servers in every ISP PoP.
7 replies →
That's still a thing. Happens to me as we speak.
For me it just doesn't resolve at all on Cloudflare dns. So annoying.
[dead]
Irony:
The author of the personal blog post claimed he works for Google, who has arguably the world's most complete web archive and uses it for commercial purposes
This archive used to be publicly accessible, at least in part, at webcache.googleusercontent.com^1
The blog post compares the size of archive.today with archive.org (about 1:40, according to the author)
But it does not include a comparison to cache.googleusercontent.com
1. Bing, another Google competitor, also offered part of their own archive at cc.bingj.com during that time
OP frames this like they just stumbled across the blog post but they created an account matching the name discussed within it three months ago?
I’m confused.
Sometimes HN admins revive quality posts that didn't get much traction when they were first posted. When this happens, the timestamps are updated to make the post look new.
I can't say for sure whether this is what happened here, but it is a possible explanation.
This post did in fact go through the second-chance pool: https://news.ycombinator.com/item?id=11662380)
Gyrovague here, author of the targeted blog post:
https://gyrovague.com/2023/08/05/archive-today-on-the-trail-...
In the past week or so, I have received a GDPR takedown attempt of the archive.today blog post (which my hosting provider rightly rejected), a politely worded request to take it down (which was sadly eaten by my spam filter), and now this (thanks to the HN reader who tipped me off).
Given that the proverbial cat has been out of the bag for 2.5 years at this point, I'm genuinely puzzled as to what they're hoping to achieve, but this does not seem like a very good way of going about it.
Sockpuppet/troll unless you link the HN thread in the blog. rabinovich OP while the article talks about "Masha Rabinovich." I suspect it's all a ruse for the FBI.
> Sockpuppet/troll unless you link the HN thread in the blog.
I've had email correspondence with gyrovague where they've shared this exact sentiment.
Great article, is the attack affecting you in any way?
Do you know when it began?
And what do you think of the account reporting this being named rabinovich, and having being created months ago?
What did the politely worded request say, was it from the creator?
I will not be sharing any discussions publicly until/unless we come to an agreement, but yes, at least it appeared to be.
Given it's set to generate random pages on the site, is there even any possible explanation for this that isn't sketchy?
It's not random, setting the query string to a new value on every fetch is a cache busting technique - it's trying to prevent the browser from caching the page, presumably to increase bandwidth usage.
It's trying to prevent the server from caching the search. Thousands of different searches will cause high CPU load and the WordPress might decide to suspend the blog.
https://news.ycombinator.com/item?id=45922875
“Behind the complaints: Our investigation into the suspicious pressure on Archive.today”
There's really no interpretation of this which isn't malicious, although, not to defend this behaviour whatsoever, I'm not entirely surprised by it. The only real value of archive.is is its paywall bypassing abilities and, presumably, large swaths of residential proxies that allow it to archive sites that archive.org can't. Only somebody with some degree of lawlessness would operate such a project.
Not excusing this malicious behavior, but I have to say, the mentioned blog post is a major dick move, too. Got quite the impression of a passive aggressive undertone, and there is clearly bittersweet irony in collecting and "archiving" an archiver's personal information from long ago traces. Maybe it's all some feud between two dicks, some backstory untold. Maybe the blog author wanted some information gone from archive.today, but was denied.
Blog post author here. Nope, I was just curious, since it's quite remarkable how huge archive.today is, how widely it's used, and how little we know about it. I do acknowledge the irony of an archiver being upset by an archive of their own work though :)
All that said, the post does not actually dox anyone (as far as I can tell, every name mentioned is an alias or red herring), and the "investigation" was basically punching things into my favorite search engine and seeing what came up. If a nation state level threat actor or even one of the copyright cabals wanted to find the maintainer, they have much better ways of going about it.
1 reply →
Perhaps, and yet I've referenced this article numerous times over the years. The most important property of an archive is that it saves an authentic copy of the source material—that is to say, the archive must be trusted. If archive.today is indeed a legitimate archival source first and foremost as it purports to be, the user has a reasonable interest in investigating the people behind it so that they can come to an informed conclusion about if they can trust the archive or not.
1 reply →
It's not just for paywall bypassing. Sometimes there are archive.today snapshots that aren't in the Wayback Machine (though I think your overall point about lawlessness still stands).
For example, there was some NASA debris that hit a guy's house in Florida and it was in the news. [1] Some news sites linked to a Twitter post he made with the images but he later deleted the post. [2]
The Wayback Machine has a ton of snapshots of the Twitter post but none of them render for me. [3]
But archive.today's snapshot works great. [4]
[1] https://www.bbc.com/news/articles/c9www02e49zo
[2] https://xcancel.com/Alejandro0tero/status/176872903149342722...
[3] https://web.archive.org/web/20240715000000*/https://twitter....
[4] https://archive.md/obuWr
Archive.today has a different approach to the baseline archive technology (executing javascript at archival time and saving the DOM instead of saving and replaying server responses verbatim). Additionally, Archive.today employs a number of site specific mitigations which aren't visible to the end user. In some cases, for instance, they use accounts, but then retroactively modify the DOM to mask this mitigation. [0] While the exact strategy they use for Twitter isn't known to me, they are doing something by their own admission. [1]
[0] https://blog.archive.today/post/708008224368001024/why-isnt-... compounded with personal observation.
[1] https://blog.archive.today/post/708565142782246912/pretty-pl...
.
What's the alternative? At least they don't comply with takedown requests, which can't be said about archive.org who remove everything even semi-controversial.
Pretty sure that blog is hosted on Wordpress.com infrastructure so it's not like the blog owner would even notice unless it generates so much traffic that WP itself notices.
That said I don't think there's many non-malicious explanation for this, I would suggest writing to HN and see about blocking submissions from the domain hn@ycombinator.com
[flagged]
DDosing but still archiving:
https://archive.is/https://gyrovague.com/2023/08/05/archive-...
I just tried in my browser (Firefox on Ubuntu) and got the same result. Deeply curious.
While many people here on HN seems to be pro archive.today, please remember that it's a website managed by pro-Kremlin people, who, among other things selectively choose which content to erase, and track visitors and archivers in a few sneaky ways (look at the HTTP / DNS requests when you visit / archive pages).
One has to wonder why all this tracking from administrator(s) that want to stay anonymous?
You can't trust anything hosted on archive.today because you can't trust that the content hasn't been altered in some way in the pursuit of their agenda.
Hm, a pro-Kremlin website, banned on Russian state firewall while actively used by Myrotvorets and many gov.ua sites....
And that's how advertising works, folks. If someone wants a website dead, I want to know more about it.
Worth blocking the URL for users of that Archive site then, avoid extra burden?
How would you determine who is a user of the archive site?
They might need to tweak a single word. Streisand readers won’t have a clue which.
Save the page now and compare a week later.
https://news.ycombinator.com/item?id=46628734 makes some good points, it shouldn't have been downvoted do death
Did you save it?
It's accessible again now